P4a : Analyse de performances de différentes structures
Problème
Description du Problème :
Nous allons comparer les différences de performances sur 3 opérations communes à différentes structures de données (tableaux, LinkedList et ArrayList). Nous allons également réimplementer ces opérations nous même et à nouveau comparer les différences de performance. Nous avons choisi d'utiliser le language objet java.
Opérations :
- Ajout d'un élement à une certaine position (n'exite pas pour les tableaux standards, add() pour les LinkedList / ArrayList)
- Suppression d'un élement à une certaine position(n'existe pas pour les tableaux standards, remove() pour les LinkedList / ArrayList)
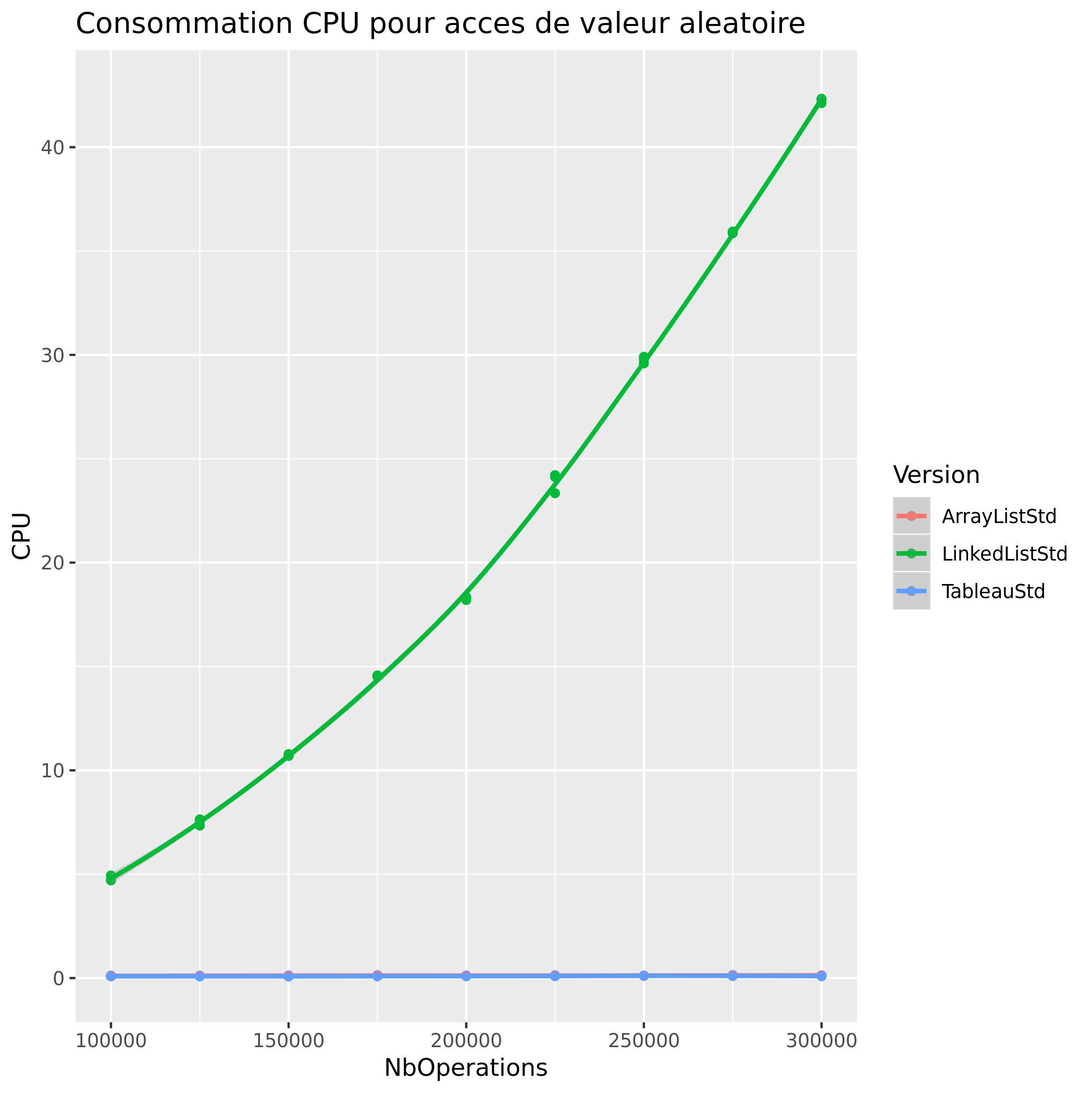
- Accès d'un élement à une certaine position(tab[position] pour les tableaux, get() pour les LinkedList / ArrayList)
Dispositif expérimental
Organisation objet
Voila notre diagramme de classe explicitant l'organisation objet de l'application.

Toutes les structures de données vont implémenter une Interface "Struture" que nous allons créer et qui contiendra les opérations choisies.
Dans le package Standard, nous appelerons juste les bonnes méthodes déja présentes dans les libraires standards et dans le package Perso nous réimplementerons par nous même ces opérations.
Application
L'application est divisée en 2 parties : les scripts shells qui appellent nos differentes classes de Main compilées en java.
Il existe un script shell pour chaque graphique et celui-ci appelle les classes Main choisies avec la commande "/usr/bin/time -f "%U,%M"
Description de l'application et des argumentsEnvironnement de test
Tout les tests ont été réalisés sur le serveur troglo.iutrs.unistra.fr
Description de la plateforme de test (extrait de /proc/cpuinfo)
processor : 1
vendor_id : GenuineIntel
cpu family : 15
model : 6
model name : Common KVM processor
cpu MHz : 2095.078
cache size : 16384 KB
siblings : 2
cpu cores : 2
clflush size : 64
cache_alignment : 128
address sizes : 40 bits physical, 48 bits virtualDescription de la démarche systématique
Voici la démarche que nous avons suivi pour génerer des données puis produire des graphiques :
1. Compiler les fichiers source dans le dossier P4A\src\p4a avec la commande javac ./*.java
2. Choisir le script shell de son choix et le copier dans le dossier P4A\src
3. Executer ce script shell pour génerer puis enregistrer les données avec la commande ./nomScript.sh > perf.csv
4. Executer la commande R pour pouvoir générer les graphiques avec ces données
5. Charger la librairie ggplot2 (commande : library(ggplot2)) puis charger les données : perf <- read.csv("perf.csv")
6. Génerer le graphique avec la commande ggplot(perf, arguments) puis exportation avec ggsave("nomGraphique.png")Chaque script shell réalise le test sur les différentes structures de données 3 fois (parametrable en changeant la valeur de la variable TESTS). Le nombre de fois que l'opération testée est executée est également parametrable via la variable NBOPERATIONS. Cette variable est une séquence de plusieurs nombre permettant d'obtenir plusieurs points sur les graphiques.
Résultats préalables
Consommation CPU
Ajout de Valeur
| Tete de liste | Queue de liste | |
|---|---|---|
 |
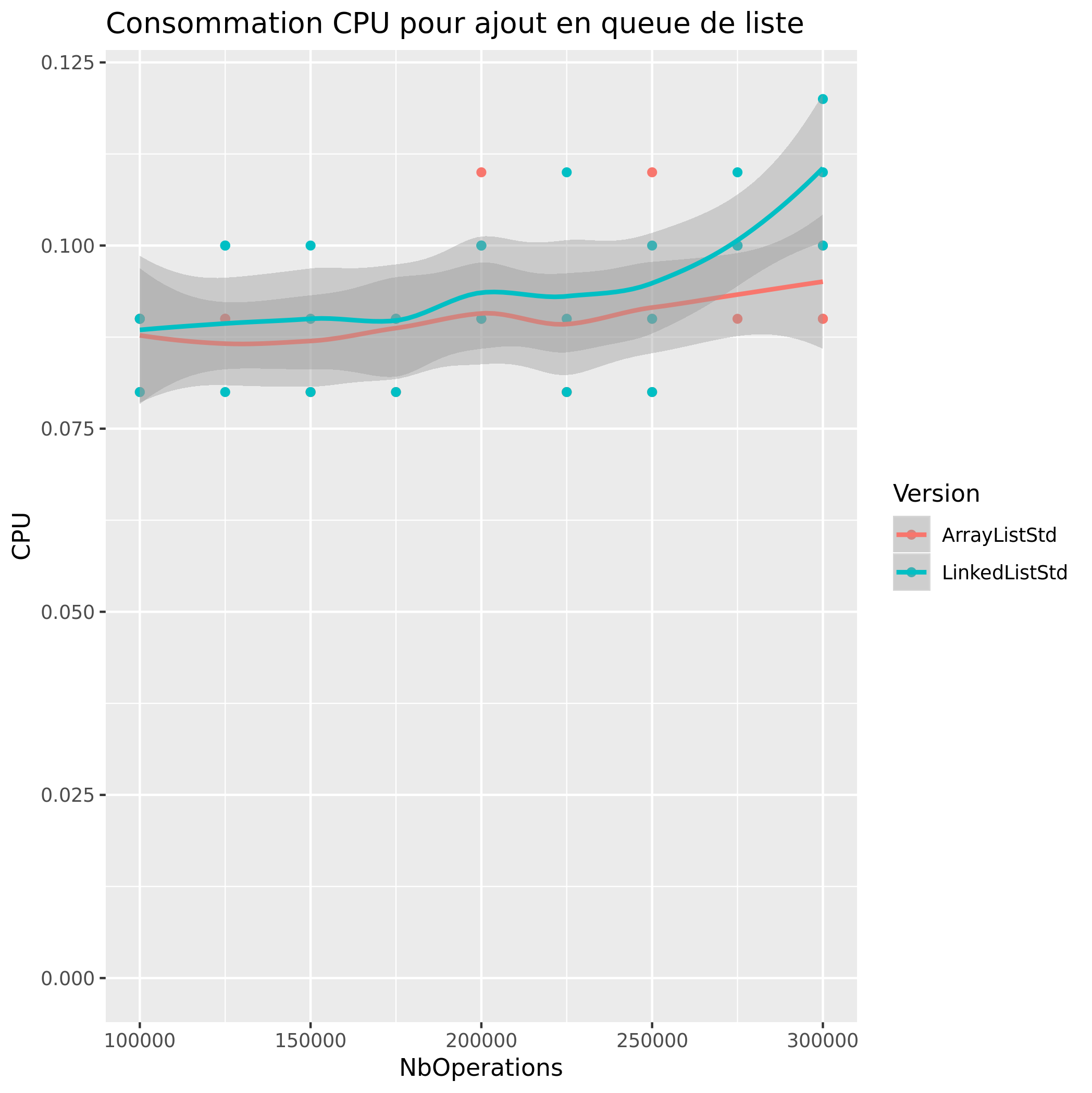 |
Suppression de Valeur
| Tete de liste | Queue de liste | |
|---|---|---|
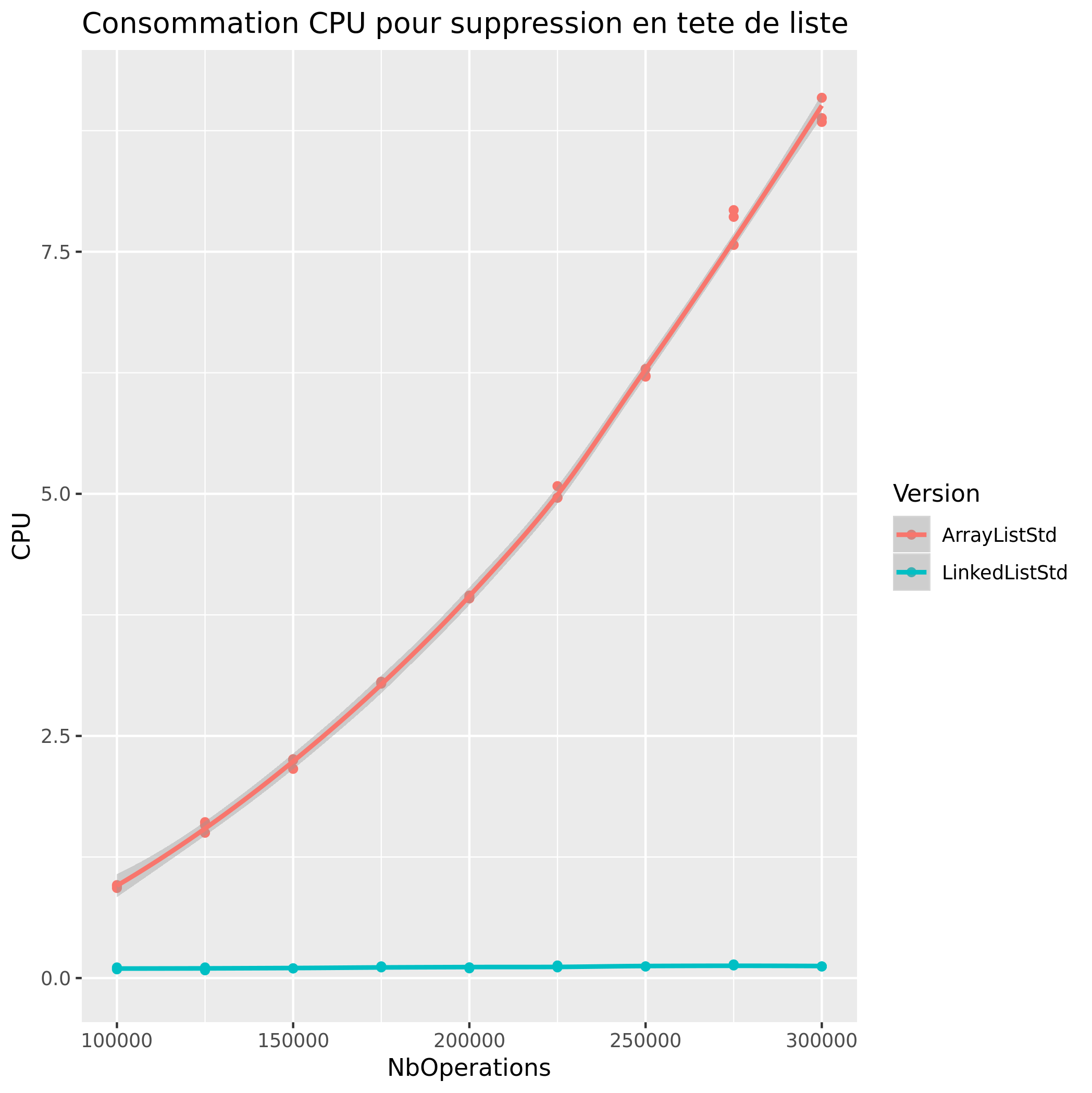 |
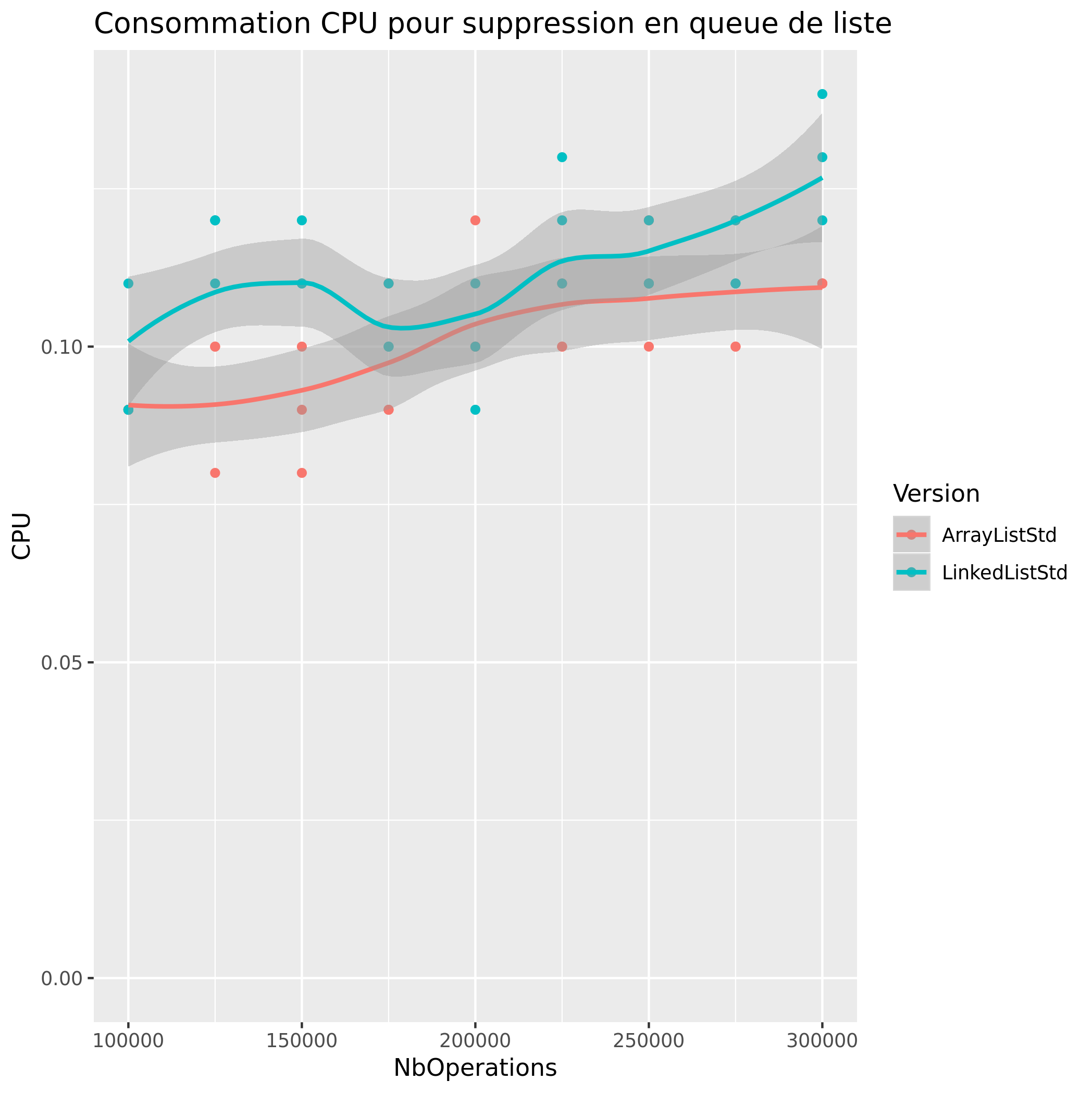 |
Assignation de valeur (tableau)
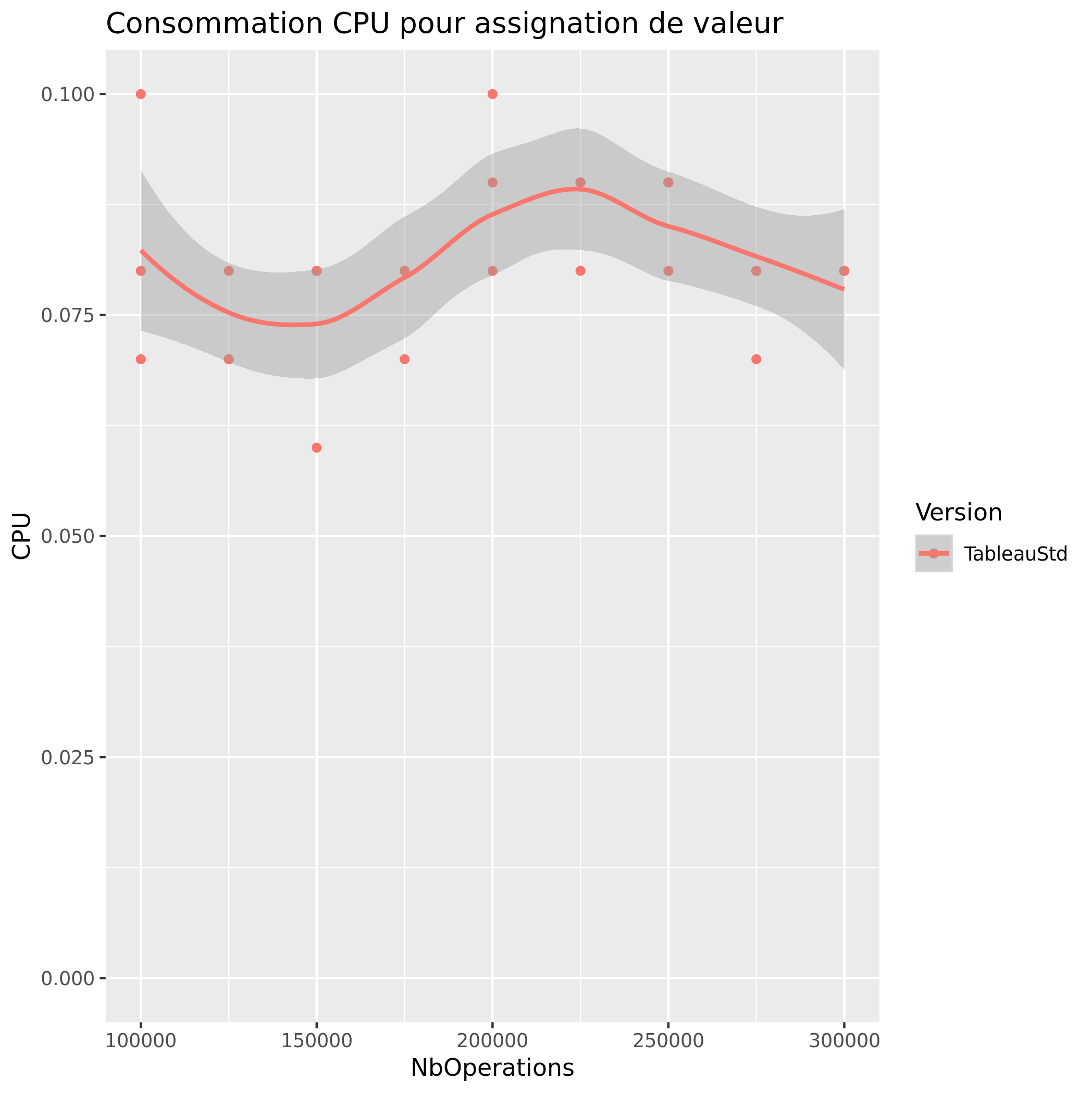
Accès de Valeur aleatoire
Consommation mémoire
Ajout de Valeur
| Tete de liste | Queue de liste | |
|---|---|---|
 |
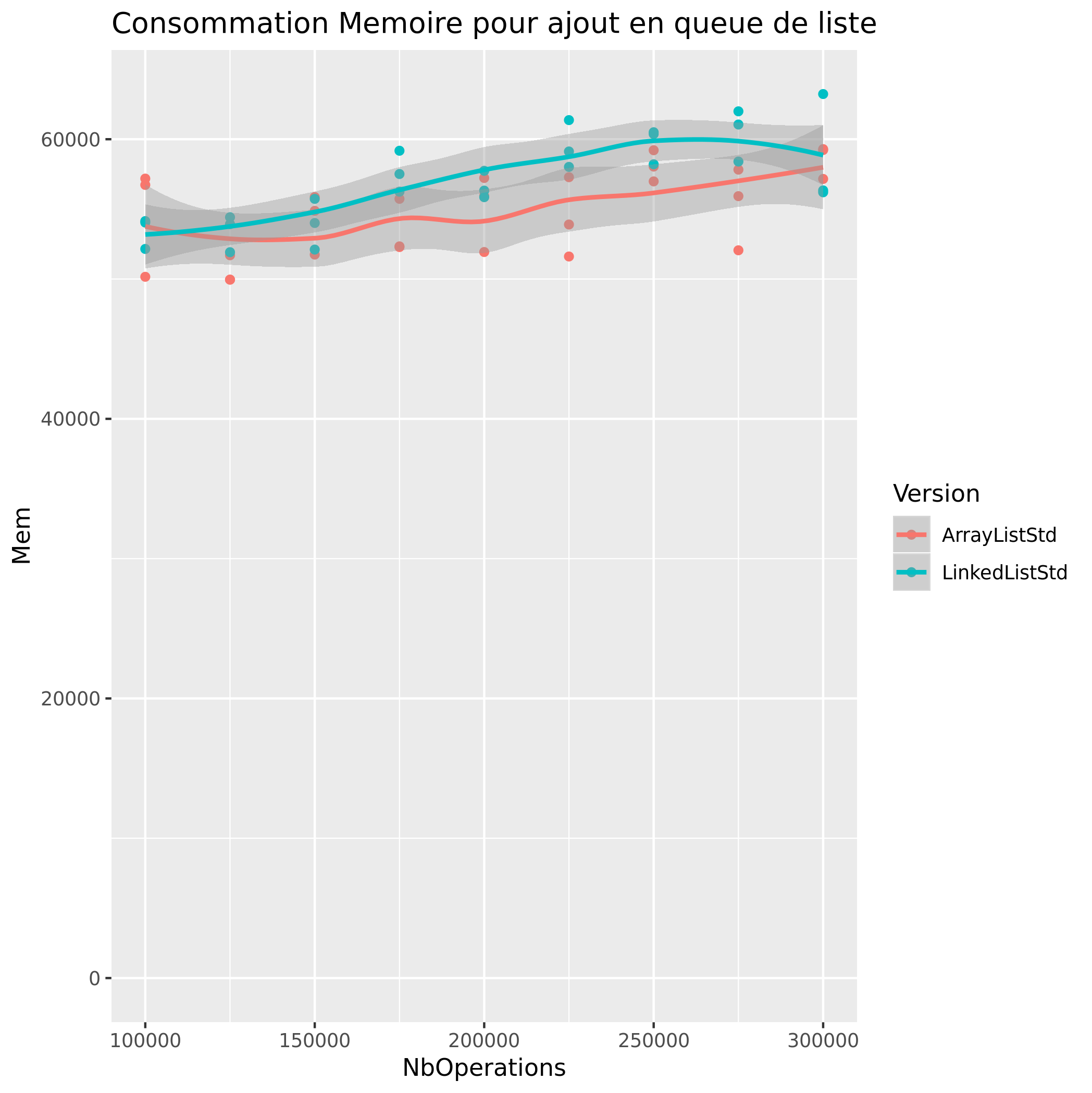 |
Suppression de Valeur
| Tete de liste | Queue de liste | |
|---|---|---|
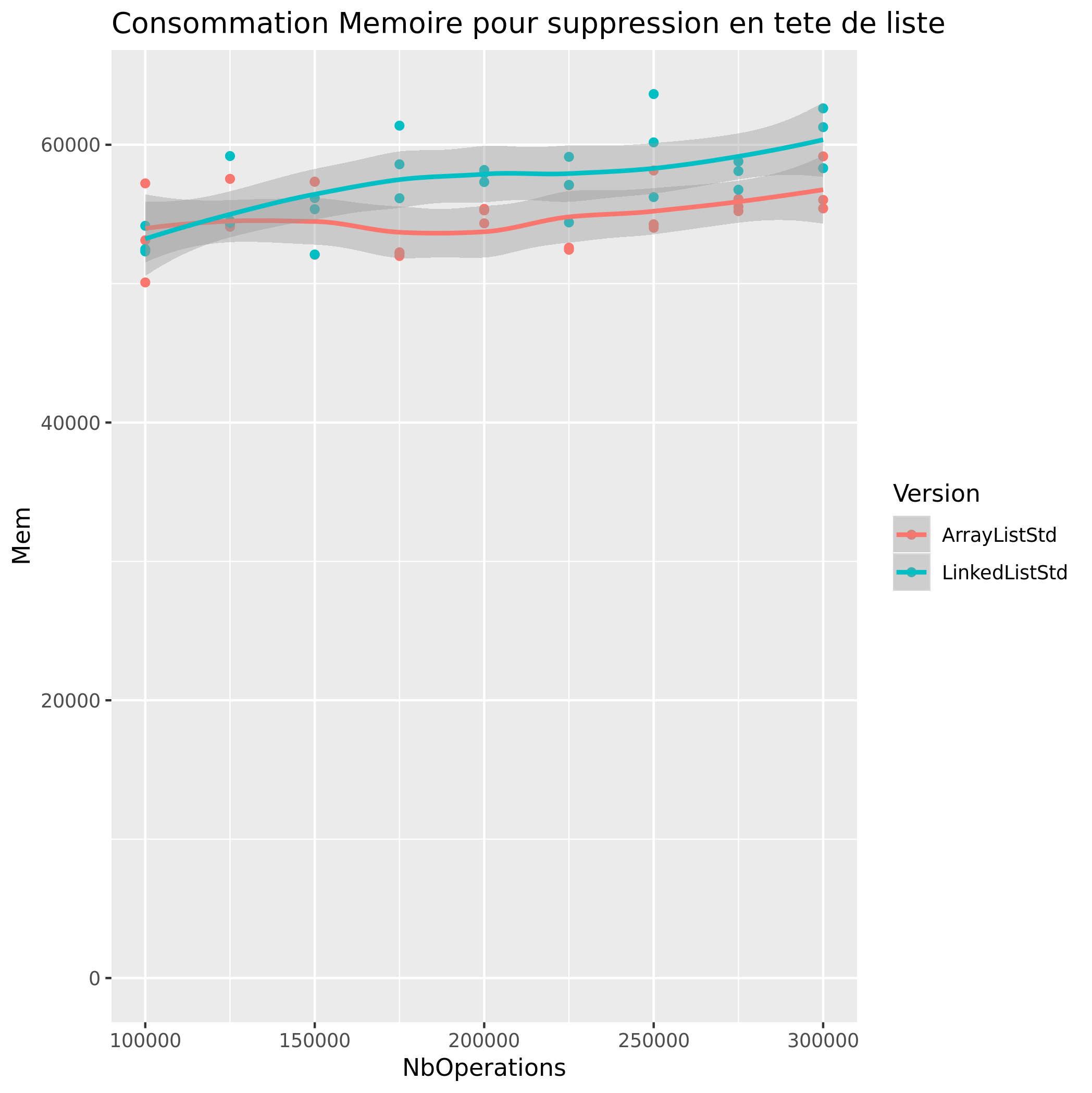 |
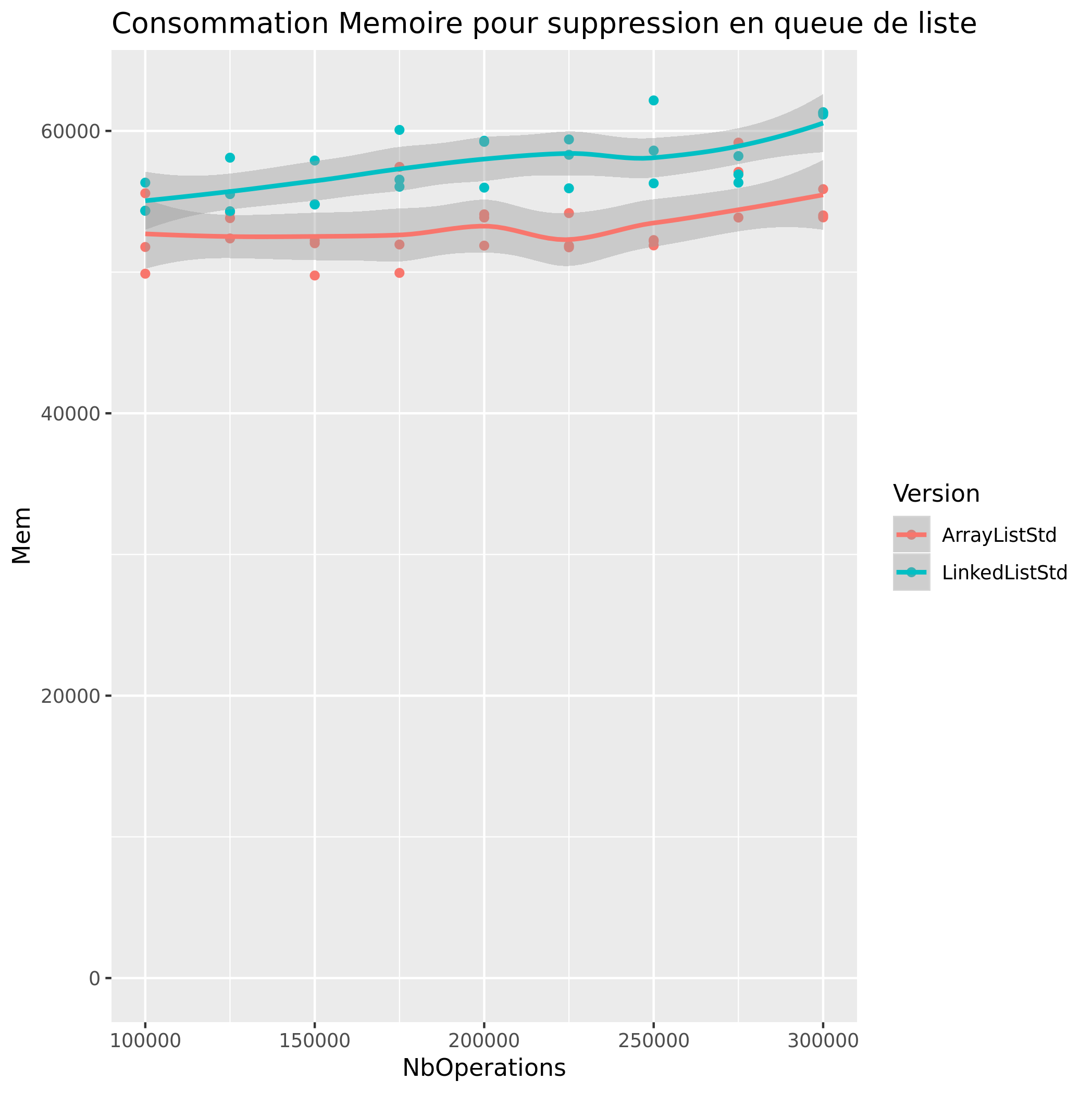 |
Assignation de valeur (tableau)
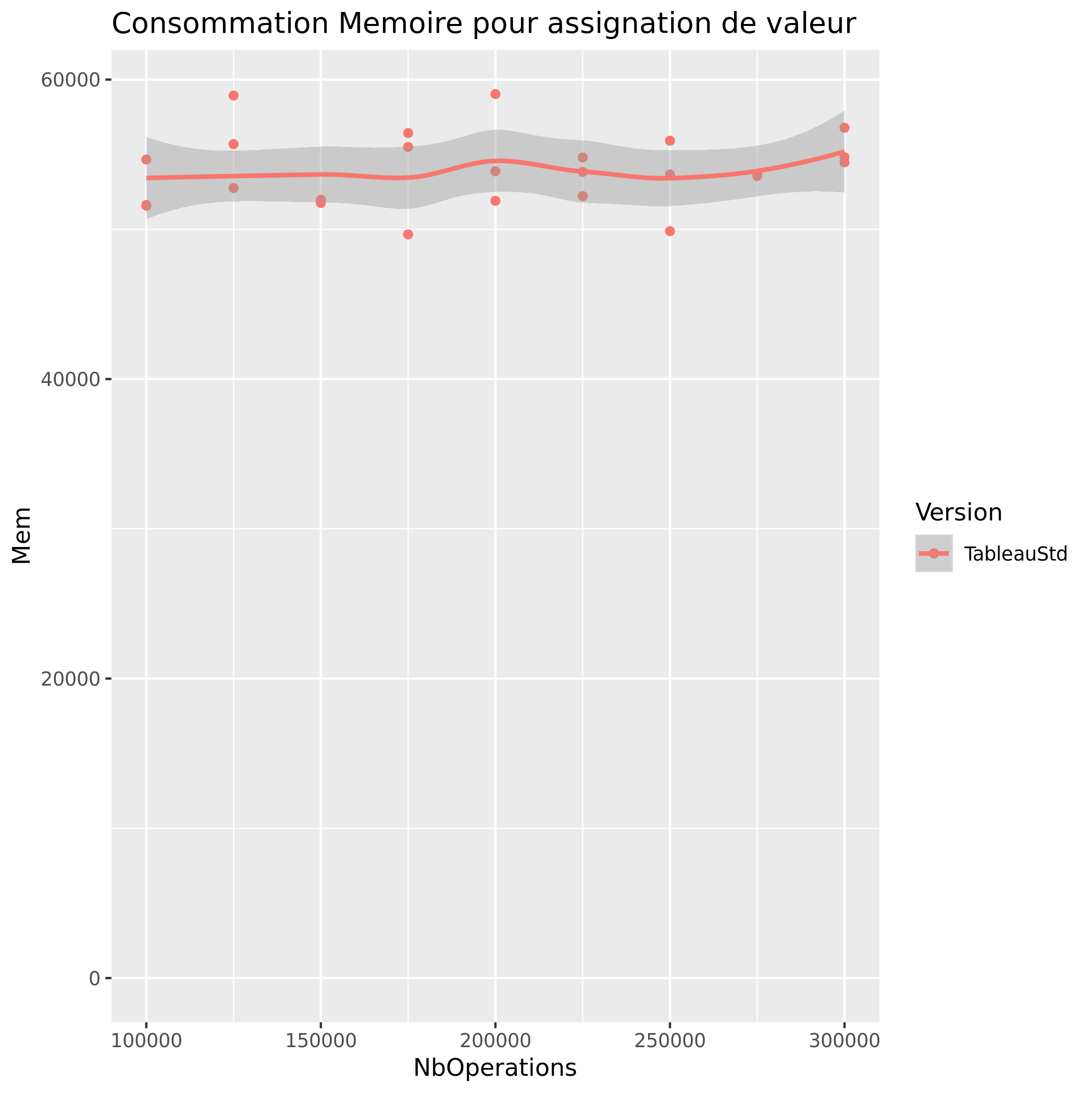
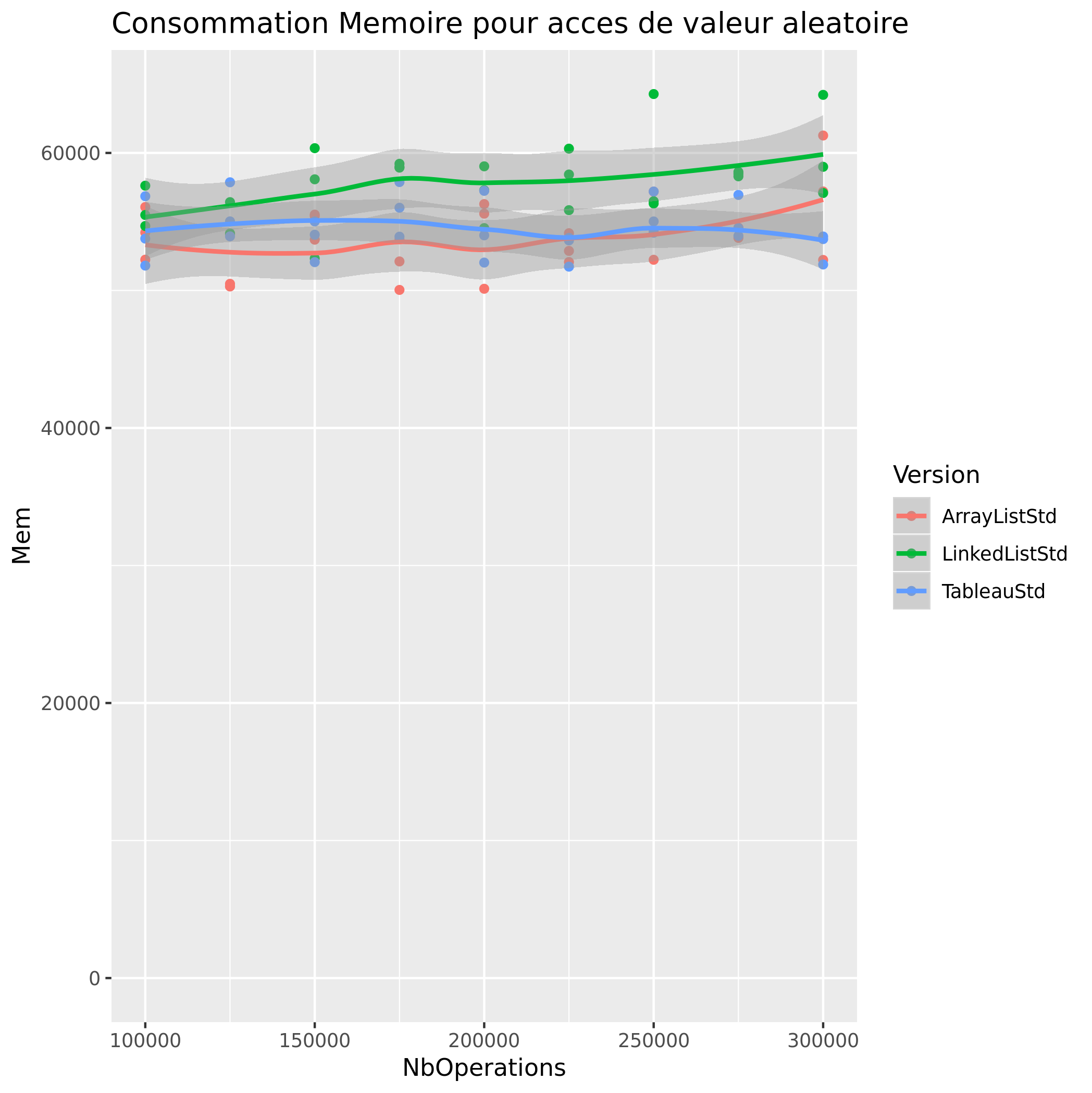
Accès de Valeur aleatoire
Analyse des résultats préalables
A faire
Discussion des résultats préalables
Explications précises et succinctes sur ce que les limites des résultats préalables et ce qu'ils ne permettent pas de vérifier.
Etude approfondie
Hypothèse
Expression précise et succincte d'une hypothèse.
Protocole expérimental de vérification de l'hypothèse
Expression précise et succincte du protocole.
Suite des commandes, ou script, à exécuter pour produire les données.