-
 pruizf authored07d1512b
pruizf authored07d1512b
Objectives
The Alsatian dialect theater tradition is based predominantly on popular and humour genres. What are the major trends in this tradition, regarding dramatic technique and character types? What are its major geographic locations? To what an extent do Alsatian dialect plays document the sociolinguistic situation of the period when they were written?
In order to answer these questions and carry out quantitative analyses, a large corpus representative of the tradition is required, as well as corpus annotations for the relevant variables: geographical origin plays and authors, places where the plays take place, their period and genre. Regarding the characters, attributes such as their profession, social status, origin, gender or age must be made available. It is also necessary to formalize the plays' structure, identifying act and scene divisions, characters' speech and stage directions.
Our project’s goal is creating such a corpus, encoded in the TEI format (Text Encoding Initiative), whose Performance module covers the types of annotations we’re interested in. We’re working on a representative collection of plays, which were recently digitized by the Bibliothèque Nationale et Universitaire (Bnu) in Strasbourg. We’re currently performing OCR on the plays and their TEI encoding.
The corpus thus created will allow a distant reading or macroanalysis approach to Alsatian theater. Such approaches have been applied succesfully to the majour European dramatic traditions, as shown in a 2017 special issue of the Revue d’Historiographie du Théâtre. However, such analyses are still impossible for Alsatian, given lack of an appropriate digital corpus. The MeThAL projects seeks to fill this void.
To that end, we will apply natural language processing and document representation techiques, besides web technologies which will contribute to corpus navigability.
Challenges
The huge orthographic variety of Alsatian presents specific challenges for Natural Language Processing (NLP), as is the case for any low-resource language. These challenges highlight needs which are only partially adressed by existing text analysis tools, mainly geared towards majority languages. The project will exploit and contribute to the resources created by the RESTAURE project, on NLP for France’s regional languages.
Outputs
Publications
-
Pablo Ruiz, Delphine Bernhard, Pascale Erhart, Dominique Huck, Carole Werner. (2020). MeThAL : Vers une macroanalyse du théâtre en alsacien. Humanistica 2020, Bordeaux, France. ⟨10.5281/zenodo.3788019⟩. ⟨hal-02564694⟩
Corpus
-
methal-sources: The TEI-encoded plays are publicly available on the University’s Git repositories: https://git.unistra.fr/methal/methal-sources
Presentations
-
Pablo Ruiz at the LiLPa Lab seminar, December 2019: [pdf]
Participants
Project participants are members of the LiLPa lab: Pablo Ruiz (lead), Delphine Bernhard, Pascale Erhart, Dominique Huck and Carole Werner.
We are also in contact with the Bnu’s Datalab and the Bnu’s special interest group on corpora (SIG Corpus).
Web presence
-
The Bnu’s research blog talks about the project
-
The DraCor platform (Drama Corpora) has accepted to host the encoded plays, making some first analyses possible:
-
dracor.org/als: Digital edition browsing, character networks and character-relation networks
-
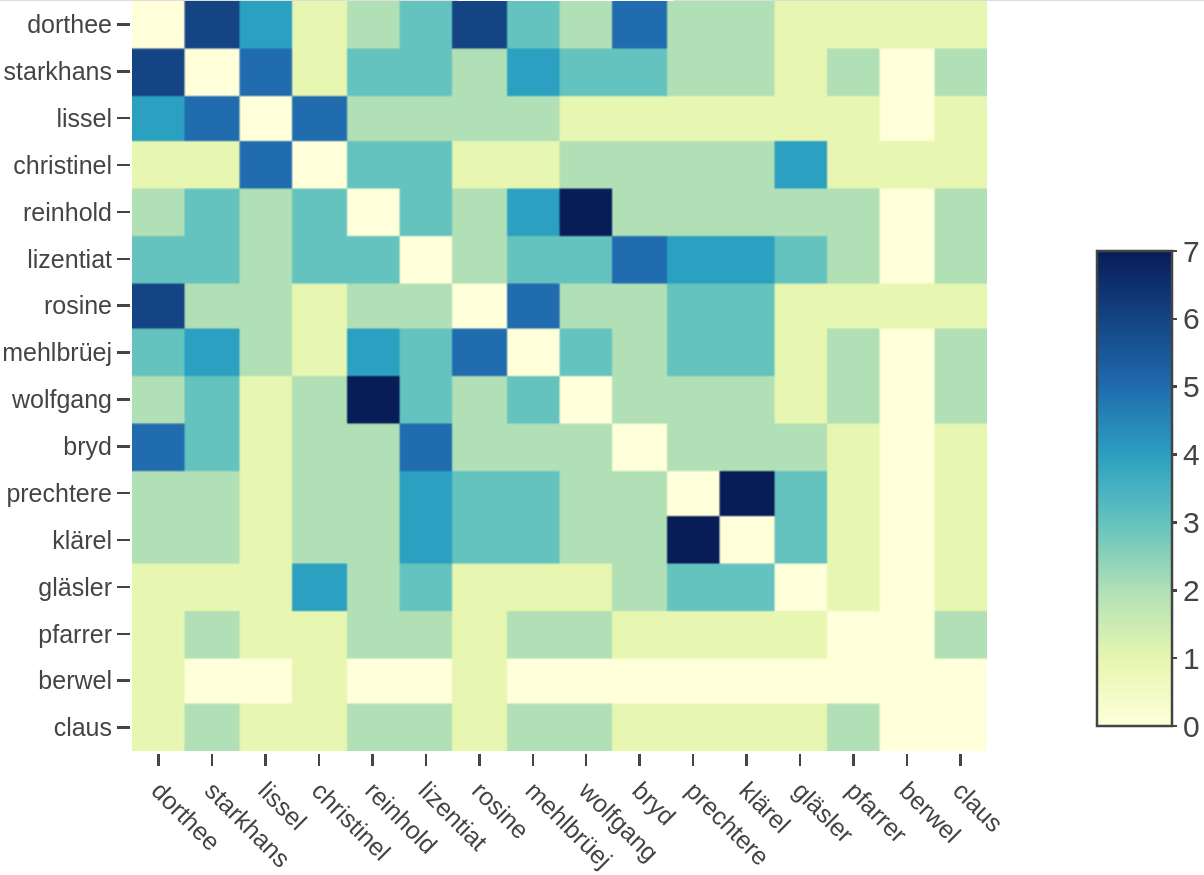
shiny.dracor.org: Character interaction metrics. For instance, the interaction matrix below, for characters in Der Pfingstmontag (Arnold, 1816).
-
Get in touch
Interested in doing an internship on OCR and TEI encoding, language technology application to Alsatian, digital editing, Alsatian linguistics or literature, or database and web development?
You have questions about the project?
Do contact us!
