-
 HEYD CLOE authoredbd7a9671
HEYD CLOE authoredbd7a9671
- P4a : Analyse de performances de différentes structures
- Problème
- Dispositif expérimental
- Organisation objet
- Application
- Environnement de test
- Description de la démarche systématique
- Résultats préalables
- Temps d'exécution
- Dézoomé
- Zoomé
- Consommation mémoire
- Analyse des résultats préalables
- Discussion des résultats préalables
- Etude approfondie
- Hypothèse
- Protocole expérimental de vérification de l'hypothèse
- Résultats expérimentaux
- Analyse des résultats expérimentaux
- Discussion des résultats expérimentaux
- Conclusion et travaux futurs
P4a : Analyse de performances de différentes structures
Problème
Langage utilisé
Nous avons choisi d'utiliser le langage Java car il est plus adapté à notre organisation.
Description du problème
Analyse de performance de quatre structures identiques contenant des nombres mais fonctionnant différemment.
Nous aurons plusieurs paramètres au démarrage :
- Nombre de valeurs dans chaque tableau : chaque structure a une taille fixe de un million d'éléments générés aléatoirement.
- Nombre d'opérations : à chaque test, on augmente le nombre d'opérations de 100. Le nombre d'opérations varie de 100 à 5000.
- Type de l'opération : AddTete, AddQueue, RemoveTete, RemoveMiddle ou Get.
- Type de structure : nous utilisons des structures déjà existante (ArrayList, LinkedList, Table) et que nous avons créées nous-même (ChainedList composée de Link et d'un Cursor).
Contrainte : il faut de l’abstraction, et au moins un tableau ET une liste chaînée (Maillons)
Description des paramètres exploratoires du problème
- Analyser la différence de temps d'éxécution CPU et de consommation de mémoire sur des opérations simples dans chaque structure (insérer, supprimer, sélectionner).
Organisation du projet
Dispositif expérimental
Organisation objet
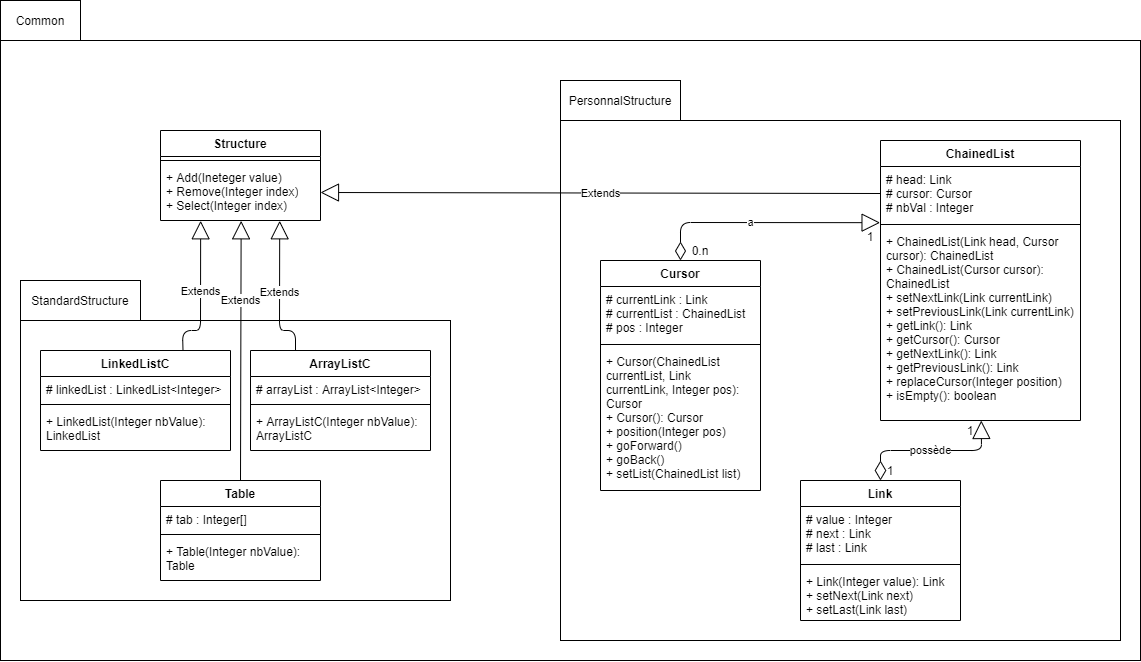
Description de l'organisation des classes et interfaces
Nous avons utilisé trois packages différents :
- Un pour les structures déjà existantes, StandardStructure : ArrayList, LinkedList et Table.
- Un pour celle que nous avons créée, PersonalStructure : ChainedList et ses composants, Link et Cursor.
- Un pour ce qui est commun aux deux packages précédents, defaultpackage : Main et Structure.
Pour les structures déjà existantes, nous avons préféré recréer une classe wrapper pour chacune d'entre elles afin de personnaliser les fonctions que nous voulions tester et adapter leur fonctionnement à chaque structure.
Diagramme de classes
Application
Description de l'application et des arguments
Pour utiliser notre application, il faut lui passer plusieurs paramètres dans l'ordre suivant : le type de structure que l'on souhaite évaluer, le nombre de valeurs (un million), la méthode que l'on va évaluer et le nombre d'opérations.
Le Main va ensuite créer une structure en fonction des paramètres qu'on lui a passé et la remplir de nombres aléatoires. Il va ensuite appeler la fonction choisie en utilisant un switch.
Environnement de test
Description de la plateforme de test

Description de la démarche systématique
-
taille : taille de la structure, fixe à 100 000 éléments
-
nbOperation : nombre d'itérations pour chaque opération -> effectuer une observation à plus ou moins grande échelle, va de 50 à 250 avec un pas de 50
-
operation : String de l'opération courant (Add, Remove, etc), il y en a 8 afin de pouvoir faire une observation d'ensemble sur toutes les opérations d'un coup
-
type : String de la structure courante. Il y a 4 structures (Tableau, Arraylist, Linkedlist et ChainedList) afin de pouvoir faire une observation sur chacune d'entres elles
-
Les observation sont : le temps CPU sur x nombre d'opération et la consommation mémoire.
library(ggplot2)
perf <- read.csv2("perf.csv", sep="\t", dec=".")
GraphCPU <- ggplot(perf,aes(y = CPU, x = nbOperation, colour = Structure, shape =Structure)) + geom_point() + geom_smooth() + ggtitle("Evaluation du temps d'éxecution du CPU") + labs(y="Temps en secondes", x="Nombre d'opérations") + facet_grid(.~Operation)
GraphMemoire <- ggplot(perf,aes(y = Mem, x = nbOperation, colour = Structure, shape =Structure)) + geom_point() + geom_smooth() + ggtitle("Evaluation de la consommation mémoire") + labs(y="Temps en secondes", x="Nombre d'opérations") + facet_grid(.~Operation)
GraphCPU + coord_cartesian(ylim = c(0, 1))
Résultats préalables
Temps d'exécution
Dézoomé

Zoomé

Consommation mémoire

Analyse des résultats préalables
On constate que la mémoire agit différemment uniquement en fontion des structures et non pas des opérations sur celles-ci. De plus, la LinkedList prend le plus de mémoire. ArrayList est la structure qui prend le moins de consommation mémoire, ce qui est logique car elle est implémentée de base par java et rapide dans le temps CPU.
Le temps CPU varie grandement entre les structures. Bien sur, nous constatons des tendances comme par exemple ArrayList et Tableau qui sont souvent joints et LinkedList et Maillon qui sont aussi joints. C'est donc cohérent par rapport au mécanisme de la structure car on voit bien que sur les méthodes comme Add (tête, queue, random) où l'on constate que le temps CPU est le même partout, ou presque pour LinkedList et ChainedList qui prennent plus ou moins de temps sur la méthode Get, ce qui est logique car ce sont des listes chainées (le déplacement prend du temps).
Cependant, sur les méthodes Remove (tête, middle) on constate un temps CPU énorme sur tableau, ce qui est logique. Lorsqu'une valeur de tableau est retirée, il faut que tous ses éléments soient décalés vers la gauche, mais quand nous avons 1 millions d'élements ou même 100 000, cela prend du temps. Les résultats sont donc cohérents car RemoveMiddle prend deux à trois fois moins de temps que RemoveTete pour tableau. Mais à part LinkedList et Tableau, les tendances sont similaires pour les autres structures sur les autres méthodes.
Discussion des résultats préalables
Nos observation couvrent la totalité du problème, qui est ici d'analyser comment se comportent les différentes structures sur diverses opérations.
Etude approfondie
Hypothèse
Nous avons décider de comparer le temps d'exécution et la consommation de la mémoire lorsqu'on ajoute ou qu'on enlève systématiquement un objet au début et à la fin de chacune de nos structures.
Nous avons également décider de comparer le temps d'éxecution et la consommation de la mémoire lorsqu'on souhaite trouver un index de manière standard (en avançant de 1 dans les structures tant qu'on n'a pas le bon index) et de manière dichotomique (diviser le nombre de valeur par deux puis comparer si la valeur est plus ou moins grande pour retirer ou ajouter la moitié des valeurs).
Protocole expérimental de vérification de l'hypothèse
Suite des commandes, ou script, à exécuter pour produire les données.