-
 DA-SILVA MICKAEL authored47e80ca6
DA-SILVA MICKAEL authored47e80ca6
- P4z : Analyse de performances de différents tris
- Problème
- Dispositif expérimental
- Application
- Environnement de test
- Description de la démarche systématique
- Résultats préalables
- Temps d'exécution
- Consommation mémoire
- Analyse des résultats préalables
- Discussion des résultats préalables
- Etude approfondie
- Hypothèse
- Protocole expérimental de vérification de l'hypothèse
- Résultats expérimentaux
- Analyse des résultats expérimentaux
- Discussion des résultats expérimentaux
- Conclusion et travaux futurs
P4z : Analyse de performances de différents tris
Problème
Notre problème ? Comment trier efficacement des tableaux !
Et par efficacement trier des tableaux, nous entendons les trier le plus rapidement possible, en consommant le moins de mémoire possible. Pour ceci nous allons partir de 4 algorithmes de tri différents et étudier leur temps d'exécution et leur consommation de mémoire en fonction du tableau à trier (tableau généré aléatoirement, déjà trié, trié dans le sens inverse).
Dispositif expérimental
Application
code source de l'application
Pour utiliser les tris, vous avez besoin de 2 choses:
- Le binaire
tri
- Un document texte contenant les éléments du tableau, chaque élément est séparé du prochain par un espace et pour finit par un
..
Ex :4 3 11 29 .
Le binaire demande une option et un fichier, le fichier est du type de ceux définit plus haut, quant aux option il en existe plusieures :
-
-iou--insertionpour le tri à insertion -
-fou--fusionpour le tri à fusion -
-rou--rapidepour le tri rapide -
-bou--bullepour le tri à bulle -
-aou--allpour tout les tris disponibles -
-ivou--insertion-verbosepour le tri à insertion avec les affichages avancés -
-fvou--fusion-verbosepour le tri à fusion avec les affichages avancés -
-rvou--rapide-verbosepour le tri rapide avec les affichages avancés -
-gqui génére un nouveau tableau sur stdout avec une taille du tableau et un nombre max -
-gtqui génére un nouveau tableau trié sur stdout avec une taille du tableau et un nombre max -
-gtiqui génére un nouveau tableau trié dans le sens inverse sur stdout avec une taille du tableau et un nombre max
Environnement de test
Les tests se sont fait sur troglo en connexion à distance, le fichier obtenu avec cat /proc/cpuinfo est disponible ici : cpuinfo.
D'autres test (principalement pour les hypothèses) ont été effectués sur l'ordinateur personnel d'Antonin, (ce qui a déjà entrainé quelques soucis), le cpuinfo de l'ordinateur est disponible ici : cpuinfo_antonin.
Les infos "importantes" :
- Sur Troglo
model name : Intel(R) Xeon(R) CPU E5-2630L v3 @ 1.80GHz
cpu MHz : 1198.728
cache size : 20480 KB- Sur l'ordinateur d'Antonin
model name : Intel(R) Core(TM) i7-9750H CPU @ 2.60GHz
stepping : 10
microcode : 0xca
cpu MHz : 1407.683
cache size : 12288 KBDescription de la démarche systématique
Pour obtenir perf.dat contenant toutes les données (à exécuter dans src/Scripts/):
./perf.sh > perf.datEnsuite, il faut lancer R et exécuter les commandes du fichier src/R/perf.R :
R
library(ggplot2)
perf <- read.table("perf.dat", header = TRUE)
ggplot(perf, aes(x=taille, y=temps, group=tri, colour=tri)) + geom_point() + geom_smooth() + facet_grid(tri~sort) + ggtitle("Graphe des temps d'exécution")
ggsave("../Images/graphe_temps.png")
ggplot(perf, aes(x=taille, y=mem, group=tri, colour=tri)) + geom_point() + geom_smooth() + facet_grid(tri~sort) + ggtitle("Graphe des consommations mémoire")
ggsave("../Images/graphe_memoire.png")Résultats préalables
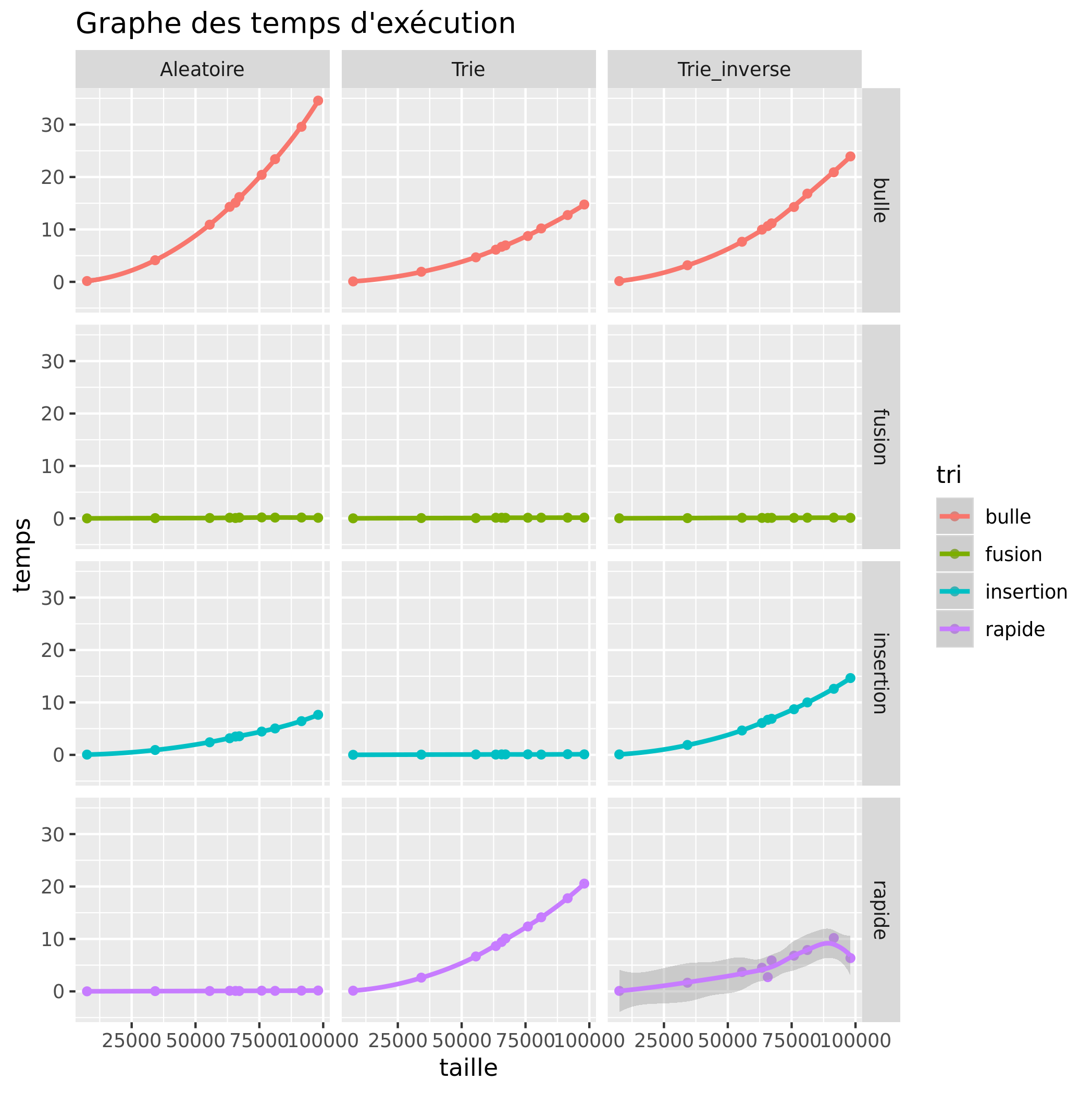
Temps d'exécution
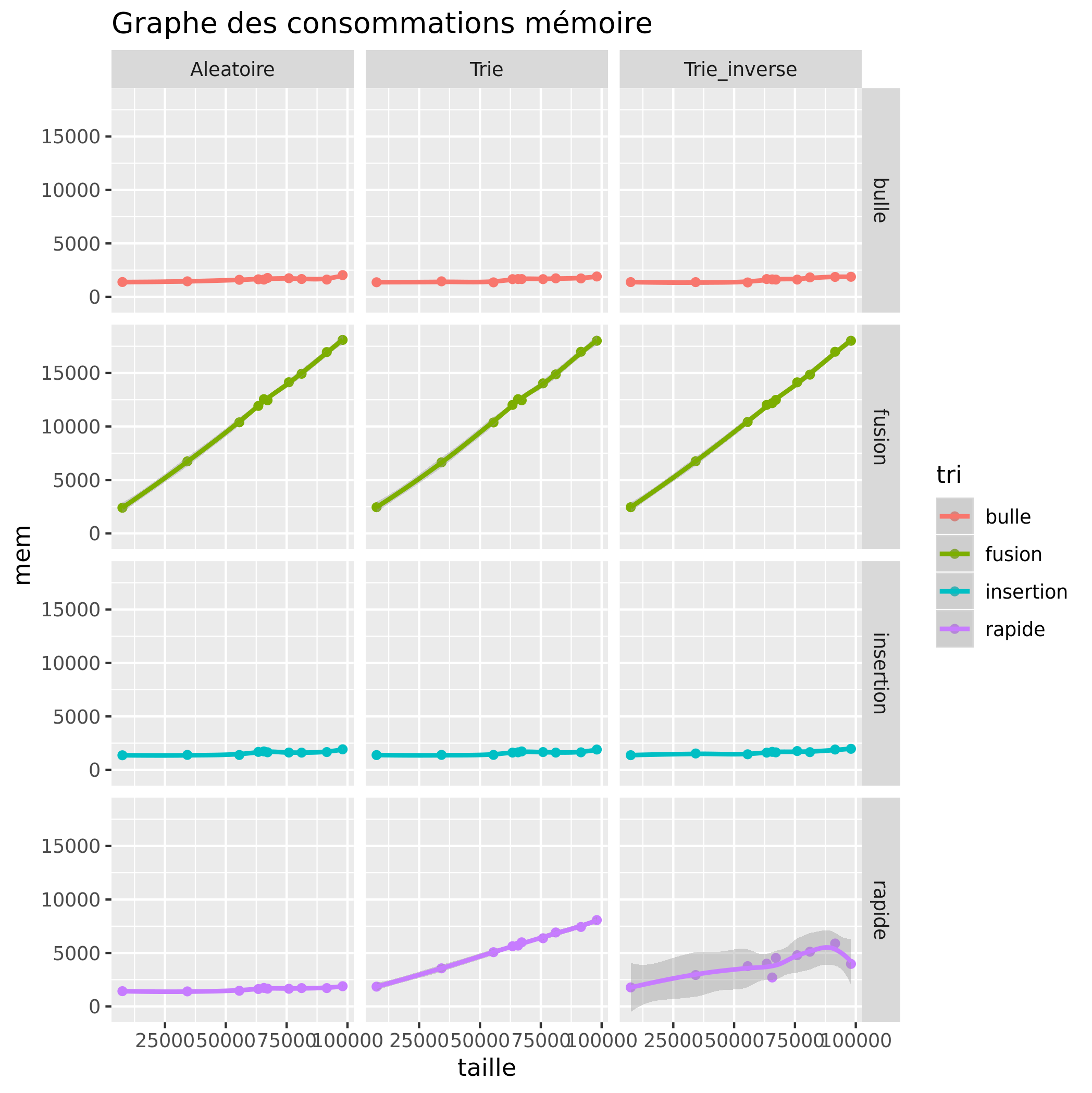
Consommation mémoire
Analyse des résultats préalables
Grâce à ces deux graphes, nous pouvons constater qu'il y a principalement 3 types de tri :
- Les tris qui s'exécutent rapidement mais consomment beaucoup de mémoire, comme le tri fusion qui consommera toujours beaucoup de mémoire, que le tableau soit de base trié, trié dans le sens inverse ou aléatoire.
- Les tris qui consomment peu de mémoire mais s'exécutent plus lentement, comme le tri par insertion qui n'a aucun problème avec un tableau déjà trié, mais met plus de temps avec un tableau trié dans le sens inverse. Le tri à bulle lui, est aussi plus rapide avec un tableau trié mais reste lent.
- Les tris qui s'exécutent rapidement et consomment peu de mémoire, plus rare, comme le tri rapide qui cependant a beaucoup de mal avec un tableau déjà trié, voir trié dans le sens inverse.
Discussion des résultats préalables
Certains résulats ne permettent pas de déduire que, par exemple, le tri par insertion est plus rapide sur des tableaux à moitié rangé. Le tri rapide s'il sélectionne comme pivot le premier éléments (ou le dernier) va se retrouver bloqué ou extrêmement lent, ces cas sont particuliers et on ne peux donc pas les déterminé simplement à la simple vue des graphiques.
Etude approfondie
Hypothèse
Le tri par insertion devient de plus en plus long quand la taille du tableau augmente, et donc celui-ci ne sait traiter efficacement uniquement des petits tableaux, étant donnée que tout les autres algorithmes coupent leurs tableaux en de plus petit tableaux. Notre hypothèse est, que si le tri par insertion est donc plus performant que les autres tris sur des petit tableaux, alors nous allons l'utiliser dans les autres tris, par exemple dans le tri rapide.
Protocole expérimental de vérification de l'hypothèse
Pour se faire nous allons donc voir si effectivement le tri par insertion se déroule plus rapidement sur plein de petit tableaux, pour le test nous avons commencé avec des tableaux de taille 100, et au lieux de regarder le temps de chaque tri de faire le tri d'un tableau puis d'un autre, etc..., on va juste prendre le temps pour trier tout les tableaux.
En faisant certains test, nous avons aussi remarqué que le tri par insertion est encore plus rapide lorsque les tableaux à traiter sont déjà presque triés.
Tout d'abord pour tester l'hypothèse on fait un petit script, ce script à été réalisé avec 1000 tableaux de 100 éléments.
./hypothese_perf.shCe qui nous donne :
Donc maintenant il faut faire un tri rapide qui utilise le tri par insertion et l'intégrer au main.