P4a : Analyse de performances de différentes structures
Problème
Lorsque l'on développe en Java, on aura souvent besoin d'utiliser des collections d'objets, sans que l'on en connaisse précisément leur fonctionnement. Chacune ayant des besoins différents, le temps d'exécution et la mémoire utilisée seront impactés par l'implémentation que l'on choisira.
On cherche donc ici à voir différentes configurations, comme par exemple:
- Quel type de collection est la plus rapide pour accéder à une donnée précise dans une collection d'objets de taille normale (~1.000 éléments) ?
- Si on se place dans une très grande collection (>100.000 éléments), quelle collection permet d'utiliser la mémoire au minimum ?
Il y a donc plusieurs paramètres qui pourront faire varier les mesures de temps d'exécution ou de mémoire en fonction du type d'opération:
- La taille de la collection
- Le nombre de répétition de l'opération choisie
Dispositif expérimental
Application
code source de l'application Java
code source du script sh
code source du script R
java -cp . main <structType> <size> <operation> <opSize>Structures analysées
- LinkedList (listes chainées)
- ArrayList (listes non chainées)
- Set (collection sans doublon de valeurs)
Opérations analysées
- add (ajoute un nombre d'éléments x en fin de liste)
- contains (vérifie la présence de x éléments dans la liste)
- remove (retire x éléments au sein de la liste)
Environnement de test
Tous les tests ont été effectués sur mon ordinateur personnel, dont un extrait du fichier /proc/cpuinfo est le suivant:
model name : Intel(R) Core(TM) i7-9750H CPU @ 2.60GHz
cpu MHz : 800.010
cache size : 12288 KB
cpu cores : 6Description de la démarche systématique
Description de la démarche systématique et de l'espace d'exploration pour chaque paramètres.
> ./code/script.sh | tee ./data/src/dataTree.tsv
> ./code/plot.rLe script plot.r lira par défaut le fichier dataTree.tsv présent à l'emplacement data/src/dataTree.tsv
Résultats préalables
Temps d'exécution
| Opération | Plot |
|---|---|
| Add | 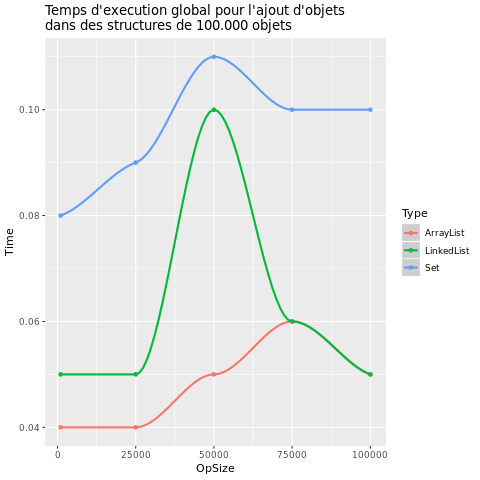 |
| Contains | 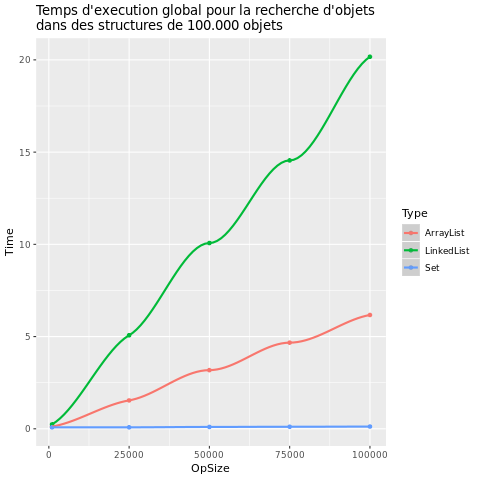 |
| Remove | 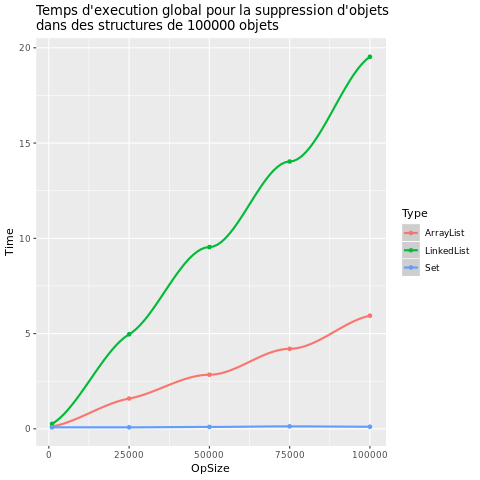 |
Consommation mémoire
| Opération | Plot |
|---|---|
| Add | 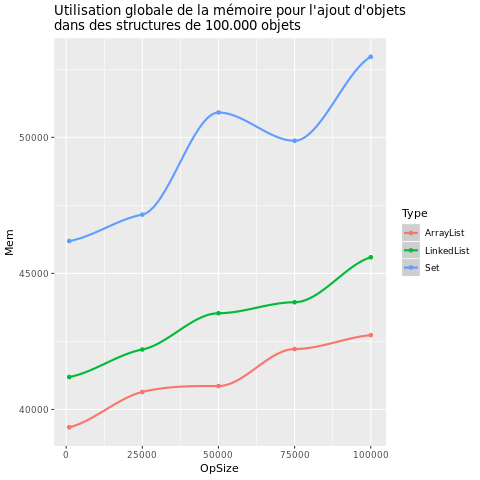 |
| Contains | 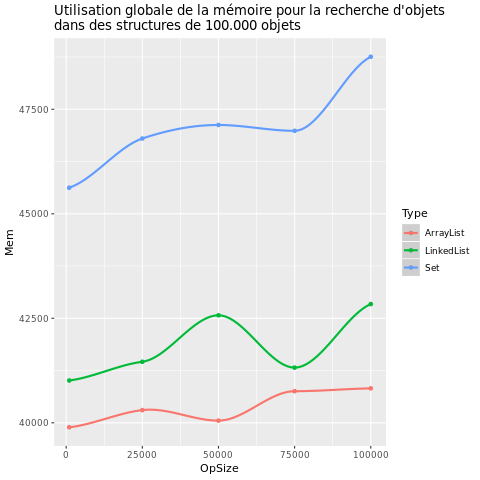 |
| Remove | 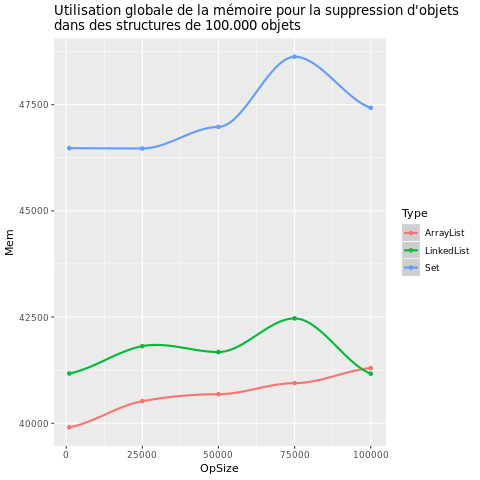 |
Analyse des résultats préalables
La première chose que l'on peut remarquer est que le temps d'exécution et l'utilisation de la mémoire varient énormément selon le type de structures.
En effet, Set est bien plus long à l'exécution que les autres qui sont très proches lors de l'appel à l'opération add.
En revanche les trois structures sont très différentes sur les opérations contains et remove:
- Set est très stable et extrêmement rapide
- ArrayList reste relativement rapide même lorsque le nombre d'opérations augmente
- LinkedList a une augmentation très proportionnelle et prend donc beaucoup de temps s'il y a beaucoup d'opérations
Pour ce qui est de l'utilisation de la mémoire, on remarque que Set en utilise toujours une quantité bien supérieure à ArrayList et LinkedList quel que soit le type et nombre d'opérations. On peut également noter que ArrayList est moins gourmande en mémoire que LinkedKist.
Discussion des résultats préalables
Explications précises et succinctes sur ce que les limites des résultats préalables et ce qu'ils ne permettent pas de vérifier.
Etude approfondie
Hypothèse
Expression précise et succincte d'une hypothèse.
Protocole expérimental de vérification de l'hypothèse
Expression précise et succincte du protocole.
Suite des commandes, ou script, à exécuter pour produire les données.